Für ein zentrales Data Warehouse, welches umfangreiche Datenmodellierungsprozesse mit vielen Quellsystemen, großen Datenmengen oder sich stetig weiterentwickelnde Geschäftslogik hat, bietet das Data Vault-Konzept eine zuverlässige und flexible Lösung an.
Kernkomponenten
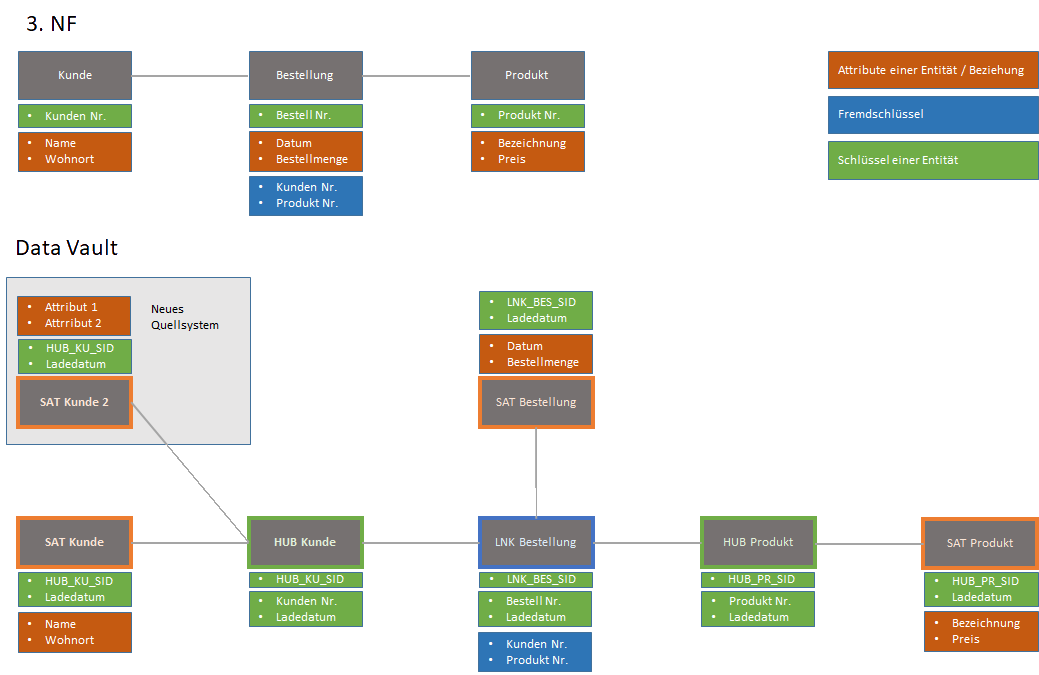
Das Data Vault-Modell besteht aus drei Kernkomponenten:
Hub
Der Hub enthält den Business Key pro Entität (z.B. Kunde). Jeder Kunde hat genau einen Hub-Datensatz. Der Hub stellt die zentrale Referenz für ein Geschäftsobjekt dar.

Link
Der Link repräsentiert die Beziehungen zwischen Geschäftsobjekten. Links verbinden zwei oder mehr Hubs miteinander und bilden so die Geschäftsbeziehungen ab.
Satellite
Der Satellite enthält die beschreibenden Attribute für Hubs und Links. Zu jedem Kunden können mehrere Satellite-Datensätze existieren, wobei bei Änderungen neue Datensätze angelegt werden.

Durch Ladezeitpunkte wird eine unitemporale Historisierung ermöglicht. Das Modell organisiert Daten nach Kategorien statt in der dritten Normalform.
Modell
Skalierbarkeit
Der Ansatz ermöglicht stabile Modelle mit inkrementeller Erweiterung. Das Anbinden neuer Quellsysteme erfordert lediglich zusätzliche Satellite-Tabellen, ohne bestehende Strukturen zu verändern.
Dies bedeutet, dass das Data Warehouse organisch wachsen kann, ohne dass bestehende ETL-Prozesse oder Datenmodelle angepasst werden müssen.
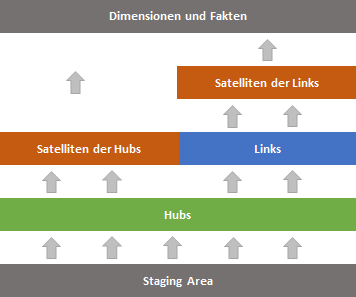
Parallelverarbeitung
Das Laden der Hubs kann gleichzeitig erfolgen, da keine Abhängigkeiten zwischen den Kategorieobjekten bestehen. Dies ermöglicht eine effiziente Parallelverarbeitung und verkürzt die Ladezeiten erheblich.
Automatisierung
Die Erstellung von ETL-Mappings kann automatisiert werden. Dazu werden Metadaten aus Datenbankmodellen (z.B. im ERwin-Format) verwendet, in XML konvertiert, durch Java-Programme verarbeitet und in ETL-Werkzeuge wie Informatica PowerCenter importiert.
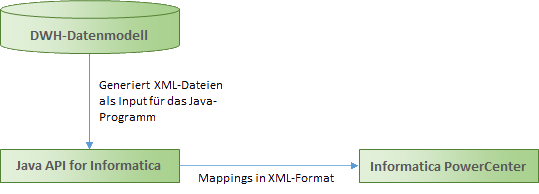
Durch diese Automatisierung wird die Entwicklungszeit erheblich reduziert und die Fehleranfälligkeit bei manueller Erstellung minimiert.
Zurück zum Blog